
In this Tableau dashboard, I chose to work with IMDB data, as I am starting a book project on horror film and its internal thematics of representation (horror films about art or artists broadly understood). I wanted to see what I could do with the genre information contained in IMDB. IMDB data is refreshed and downloadable daily in TSV. I downloaded the basic title information, which includes most of the information I was interested in, as well as the ratings information, a separate TSV. In Tableau Prep I cleaned both data sets, particularly by splitting array fields, removing nulls from the first split, removing genres that were not particularly useful (reality TV, game shows, news, and so on), and filtering to include only movies, shorts, and TV movies. I didn’t need to do much cleaning with the ratings TSV. I used an inner join connecting the “tconst” variable in each, which is the unique title ID.
I also experimented with the title AKA file, which contained region information, but this information was associated with particular titles, rather than the original film itself (for instance, I wanted to show a map of where the most horror films or horror subgenres were made; the title AKAs file connects region info only to the specific iteration of the title name—a title version assigned in Canada, in Thailand, and so on. The “original title” and “ordering” fields were not helpful for filtering, weirdly. I further tried to bring in multiple files, particularly those dealing with the principal people involved in the title and the names file to identify them. However, this proved very complicated—each name was associated with up to 4 titles, and I could not figure out how to use the relationships or noodles to make that work in any meaningful way. I may set up an appointment with you to try to figure that out! I had problems with text formatting in Public, and I removed the timeline page interaction because Public was not representing it as I wanted.
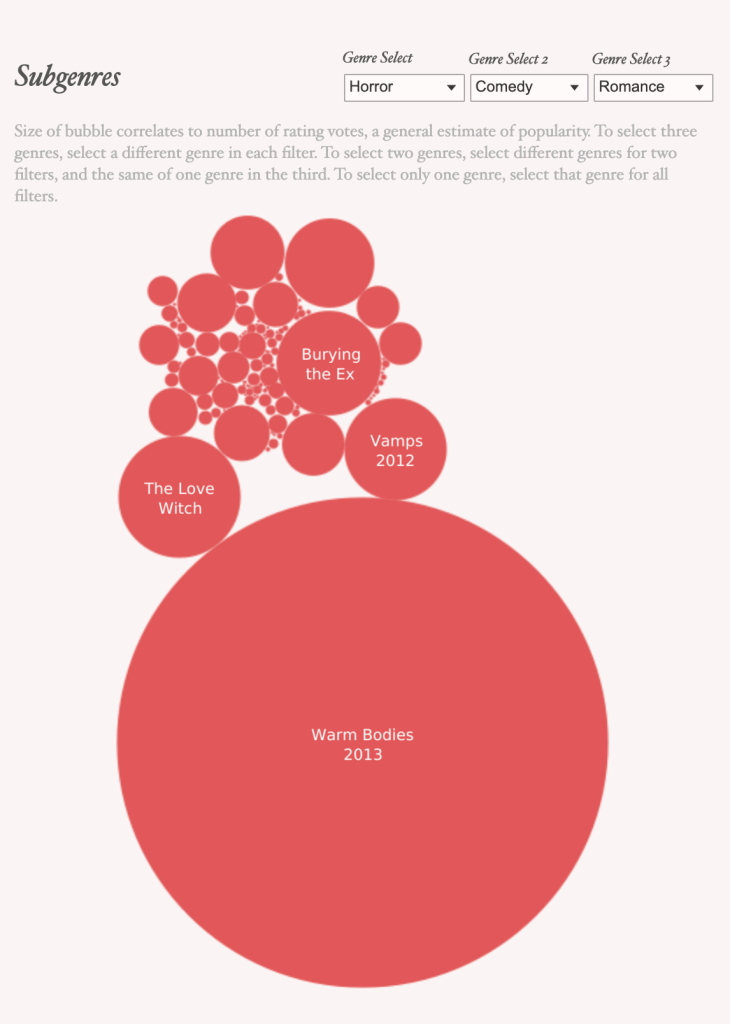
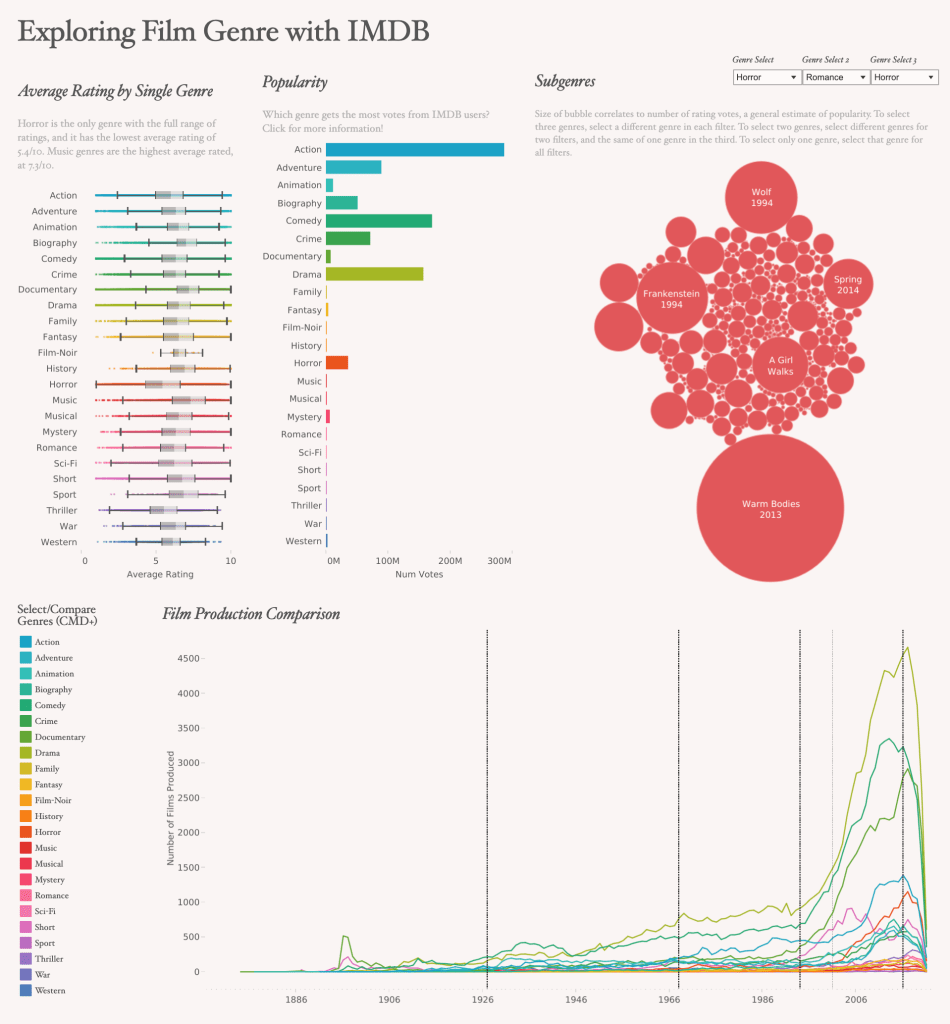
I built a visualization with minimal interaction (outside of tooltips), because the data fields were slightly different between some of the visualizations and I didn’t want things to get confusing. I created two boxplot charts for ratings by genre and number of votes by genre, drawing on the first genre split field, to get a general sense of how people felt about and interacted with the IMDB titles. IMDB data is all user-generated. Then, I added a bubble chart with selectors for genres. These genre selectors are based on calculations to compare a selected genre with the genres array field in the original data, so it is more robust than the individual splits themselves. I tried to create a concatenated genres parameter, but it didn’t quite work as expected, and after reaching out online, via slack, and to the professor, I decided my workaround was good enough for the time being. Currently, if users want to see films that were assigned three different genres, that’s straightforward. But, if users want to see only films of one genre (or two), the genres need to be duplicated, because there is no “none” feature. Then, I created a timeline to show film production by genre over time, with reference lines for key historical/cultural moments (the beginning of the sound era, the end of the Hays Code, the beginning of the 24-hour news cycle, 9/11 attacks, and the era of Trump/Covid (lumped together principally for readability). Users can command-select to highlight multiple genres, which also highlights the ratings and number of vote information for those genres; or, users can keep [them] only to see comparisons without the other marks. I was interested in genres, subgenres, and the relationships between genres and contextual factors (like ratings, voting habits, and history).
