
As the python scraper continues to do its thing, I’ve started to play around with some of the resulting data. There have been a few bumps along the road (read: several major potholes), including difficulty pulling in large chunks of text from the synopsis page of each relevant film; I think it’s also a problem that is rearing its head on summaries/storylines, but I’ll deal with that problem when I have to. For the meantime, I’ve tweaked the code to not pull synopses at all. As you’ll see, I’ve been working, as a result, with several datasets–some larger than others. None of these datasets are in their final stages, but I just couldn’t way to start digging around! Eventually, I should have around 10,000 rows of data in 16 columns (I think).
So, while the scraper was going, I was pulling the output file into my Jupyter notebook to see what was happening:

Happily, this is working for the time being–I had a weird situation earlier where the data was sort of extended across double the number of columns, and all the content was in the wrong place. I’ve had to restart the scraper several times, and I still don’t know what the problem was, but I’ve been able to work with some bigger data from earlier python passes to ask a few questions about horror films in IMDB using Tableau.
First, I wanted to see what if any relationship existed between the total number of films produced by decade and the number of horror films produced by decade. I created a calculated field (thanks, Google!) to turn integer dates into decades, and then looked at the data in tabular form.

I then created a couple of simple line charts–the ones on the bottom use dual-axis to compare, in non-synchronized axes, total film production to horror film production. You can see that overall, horror films make up a small percentage of the total overall films. What does this look like in terms of percentage? With a smaller axis range, we might be able to see something interesting. I created a calculated field that allowed me to see the proportion/percentage of horror films to all films, and you can see that there are peaks in the 1880s and 1980s–and that there’s a steady increase from the 1900s on up to the peak of the slasher period. My scraper kicked out at about 8000 rows, and IMDB data is (in general) chronological. But, from an earlier exploration of IMDB data, it was very clear that around 2019 film production dropped off dramatically (I wonder why???). So, we’ll just have to wait and see what more complete data shows.

Also curious about the number of art-horror films, I created a calculated field (thanks, Google!) using the CONTAINS function to search the Storyline text dimension for relevant keywords. I can add more to this list as I go on, but this gets me started:

Where do horror films with these keywords fall in terms of overall film ratings? In the line chart below, they seem to be on the lower end of the ratings, but we have to keep in mind that the number of films being produced is increasing dramatically–and horror films are overall a bit lower-rated as a genre, too.

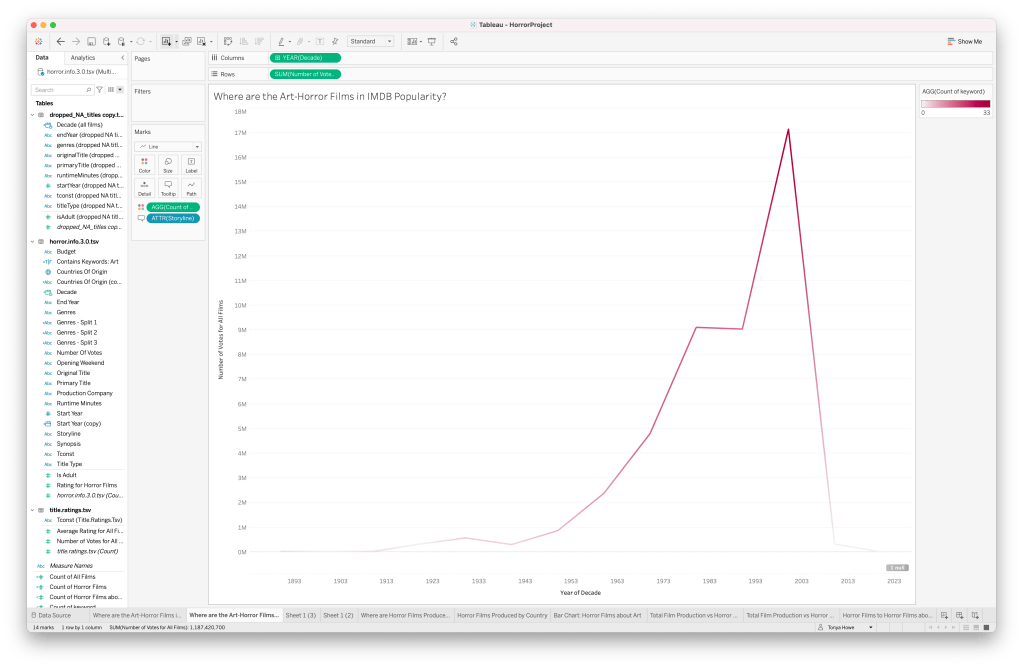
When we look at popularity, which can be gathered in some measure from the number of votes cast, we see a very different trend–these films appear to be rated more energetically, on the higher end of the number-of-votes measure in all IMDB films. I’m withholding a lot of judgement in these early stages, because I don’t have all the data and I’ve also just begun to take a look. I’m not sure the way I’ve set up the chart is telling me what I think I want to see (or at least, what I want to ask the data).
Where are horror films produced? Here, the inital data shows the US is the largest-producing country in general. But, the data needs some work. For instance, I know that the scraper pulled the Countries of Origin field in as an object, and that many of the data points in that field are multiple countries, separated by a comma. I’ll need to find a way to disaggregate them and then aggregate them in an appropriate manner. I wonder if art-horror (narrowing for keyword) changes this map in any interesting ways?

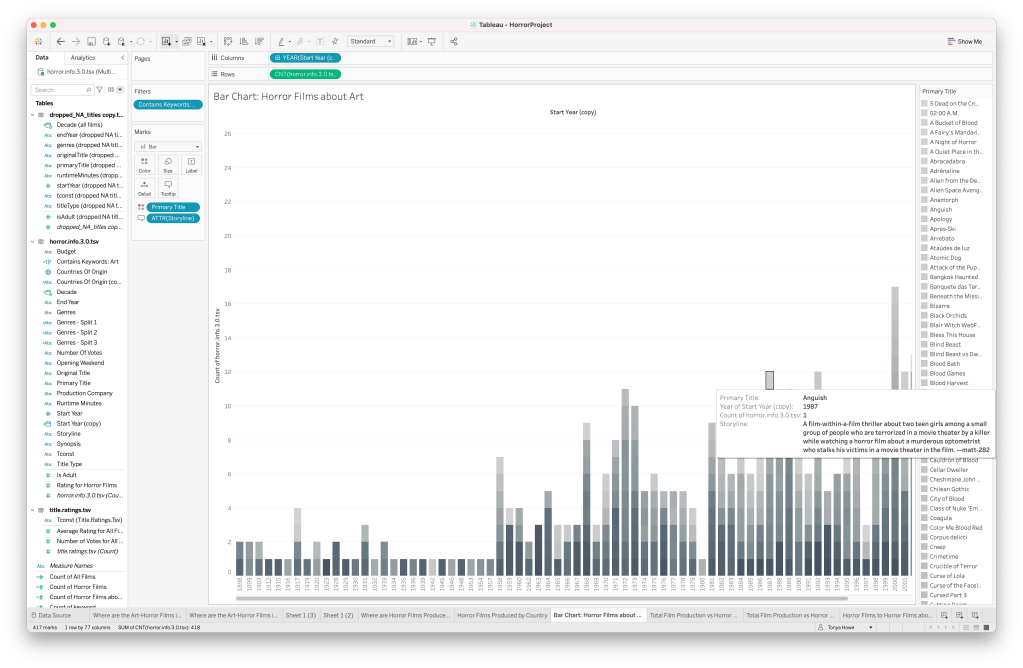
Digging a little deeper into my thematic interest, I wanted to see how many and what kind of films I’ve missed in my own viewing history. I created a stacked bar chart to show by year the art-horror films (boolean filtered by whether they contain any of my keywords in the storyline/plot summary) in my earlier and larger dataset. I edited the tooltips to show the plot summary/storyline on hover. There are tons of great additions to my tiny list from the last post! Super excited to watch some of these. Some of the storylines contain keywords that are not quite relevant in their context–for instance, the author of the plot summary may have summarized something about the film in the director or filmmaker’s oevre, so the context isn’t relevant. I’ll have to dig through these and consider whether I should exclude each film, I suppose?
I really want to be able to do some network analysis with these text-based fields, and I’ve explored how to generate the data in python (basically, you have to use NLTK to lemmatize and strip each word into its own cell, then associate each word with the film’s ttconst or unique identifier). Then use those as start/end points in a network analysis.
But that is for the future. If anyone has expertise with this kind of thing, I’d love to connect!
